 How-to handle monitoring activities in SMA
How-to handle monitoring activities in SMA Compare Software on Computers
Compare Software on ComputersHighlight a couple of workbook features
Workbooks provide a flexible canvas for data analysis and the creation of rich visual reports within the Azure portal. They allow you to tap into multiple data sources from across Azure and combine them into unified interactive experiences. Read more at the source, Microsoft Docs.
Vanessa and I have put together a workbook to visually report on computers missing updates. This can be done with Kusto queries in Log Analytics. Still, with workbooks, you can visualize it in a better way and make this visualization available to colleagues. It is also easier for someone without Kusto and Log Analytic knowledge to run a workbook.
In this example, we have to build a workbook that first lists all computers that are missing an update. We can see the computer name and the number of missing updates in the first view. If we select one of the servers, a new table is visualized, with detailed information for that computer, showing which updates that are missing. If we choose one of the updates, we get an additional table showing other computers missing the same update.



We would like to highlight some of the features used in the workbook that can be handy to know about when building workbooks.
To pass a value between queries inside the workbook, we can configure to export parameters per query item. This is set under Advanced Settings. In this example, the Computer column will be exported. To use this value in a query use {Computer}, for example
Update
| where TimeGenerated > now(-1d)
| where UpdateState == “Needed”
| where computer == “{Computer}”
| project TimeGenerated, Title, Classification, PublishedDate, Product, RebootBehavior, UpdateID
| sort by Product
Under Advanced Settings, you can also configure how to handle no data scenario. In this example, if no computers are missing updates, there will be a text saying, “Great! No servers missing updates!”.

Another handy setting is column settings. With column settings, you can, for example, rename a column in the workbook. In this example, we rename column “count_” to “# missing updates”.

The last feature we want to highlight is conditionally visible. Conditionally visible control when a query item is visible. In this example, the previous query item is not visualized until the user selects an update in the last query item. The UpdateID is exported as a parameter for the rest of the workbook.

Measure bandwidth with Azure Monitor
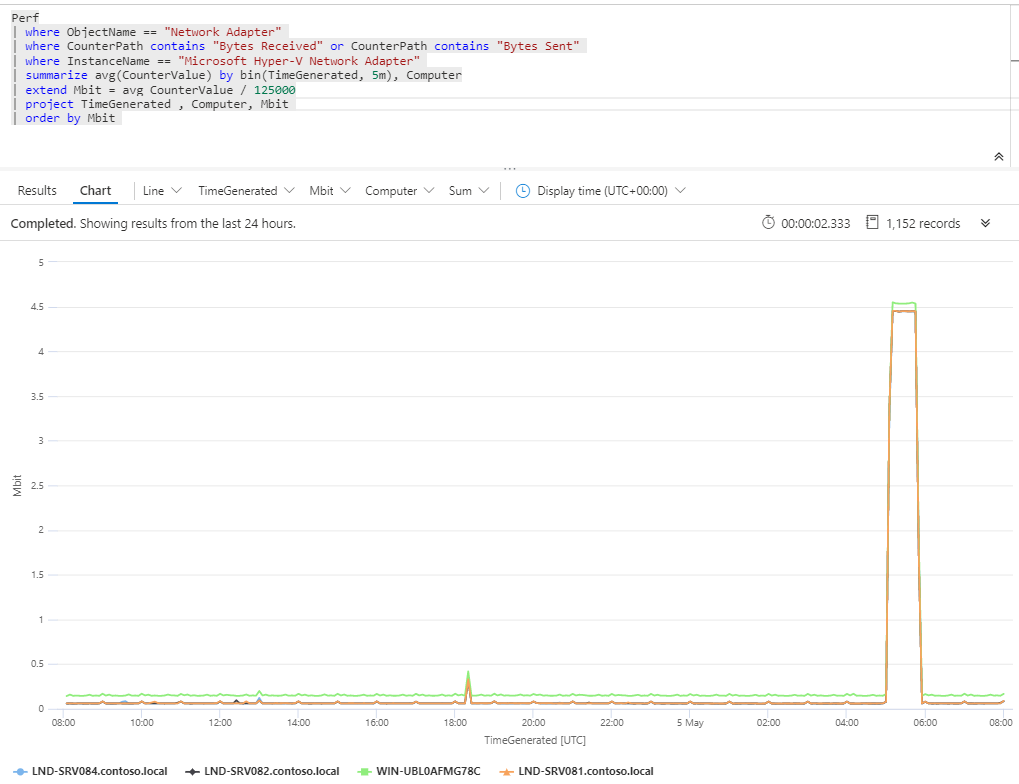
Today I want to quickly share a query that shows Mbit used for a specific network adapter.
Perf
| where ObjectName == “Network Adapter”
| where Computer == “DC20.NA.contosohotels.com”
| where CounterPath contains “Bytes Received” or CounterPath contains “Bytes Sent”
| where InstanceName == “Microsoft Hyper-V Network Adapter”
| summarize avg(CounterValue) by bin(TimeGenerated, 5m)
| extend Mbit = avg_CounterValue / 125000
| project TimeGenerated , Mbit
This query can, for example, be used in migration scenarios to estimate network connection required. The query will convert bytes to Mbit.
Sharing dashboards and workbooks in the Azure Portal
Sharing dashboards and workbooks can be a bit tricky the first time.
A key thing to keep in mind when sharing workbooks and dashboards is that the user needs access to both the workbook or dashboard resource, and its data source.
Looking at the figure below, we have a dashboard named “Contoso Dashboard†that contains several tiles (colorful boxes). Each of these tiles has its data source (black cylinder). For example, the green tile can show recommendations for Active Directory. Active Directory assessment data comes from a table in the Log Analytics workspace.
The user of the “Contoso Dashboard†then needs access both to the dashboard itself and the Active Directory assessment data in the Log Analytics workspace.

Let’s do an example. In this example, we will share a dashboard and a workbook with a guest using a Microsoft account (contoso.guest@outlook.com). The Microsoft account is not a member of our Azure AD or have any other permissions in the Azure subscription.
Sharing Dashboards
First, we create a dashboard, with only a clock, and share it with the guest account.


The guest can now access the dashboard and see the clock. Essential to make sure the correct Azure AD directory is selected; else, the dashboard will not load in the Azure portal for the guest.
If we add two tiles from Log Analytics, we can see in the left part of the image below that the guest doesn’t have permission to load the Log Analytics data. On the right side of the image below, the portal is loaded with a contributor account.

Once we assign the guest Monitor Reader permissions on the Log Analytics workspace, the guest can load the tiles in the dashboard. The Monitor Reader gives the guest access to only monitoring data in the workspace.
Sharing Workbooks
If you pin tiles from a workbook to a dashboard, the guest doesn’t need to have access to the workbook itself, and the tile will still show data if the guest has access to the data source. If the guest clicks the tile, it is only the specific tile that will be loaded in a temporary workbook. In the example below, the guest only has access to data for one of the tiles.

It works very much the same as sharing dashboards. You need to share both data sources and the workbook resource itself. If you don’t share the workbook item itself, the following error might be shown.

Using only the “Share Report†feature at a workbook will not assign the necessary guest permissions, that must be done on the workbook resource item. In my examples I have used the Reader role on the workbook resource.

You can read more about the different role assignments for monitoring data here:
Scoping monitoring with Azure services
Introduction
Monitoring is key to all modern IT operations. It is the same if we are hosting all resources in a local data center or a public cloud. Looking back, we have used, for example, System Center Operations Manager for all applications and OS monitoring, then we often had one product to monitor our hardware and maybe one for our network. Even if the goal was to use one product, we often ended up with multiple ones without any connectivity between them.
In Azure, it will be a bit different from the beginning; we will already from the start use multiple services, and then connect them in the visualizing (dashboard) and reporting (workbook) layers. A significant difference compared to the local data center is that in Azure, all services and components are built to collaborate and work together. Another key difference compared with local datacentre is that in Azure, we quickly test new monitoring features, scale up and down, and immediately support the monitoring of new business services.
In this blog post, we will walk through how to get scope monitoring with Azure services. We will begin by setting the scope and expected outcome for the monitoring solution. Instead of saying we will monitor “everything,†we will create a scope based on what we need. Saying “we will monitor everything†often ends with an outdated, unnecessary complex solution that doesn’t fulfill our requirements and doesn’t give value.
Before starting setting the monitoring scope, we recommend you read the Introduction about Cloud monitoring guide in Microsoft Cloud Adoption Framework. Â
Setting the scope
To set the scope of monitoring, I often recommend to break it down per application, as it is applications that the business use, not hard disks or network segments. Often it is per application support case will be created, and the SLA is per business application. Once you have decided which application to focus on, ask the following questions;
- What is it that you need to monitor?
For example, let us say that Contoso has a web application, including a SQL Server database, an application server, and two web servers. Those components are what we need to monitor. All servers are running Windows Server 2012, and the database server is SQL 2012. There are two critical services on the application server and four Windows events to look for in the Event Viewer. All servers also need standard performance monitoring. We also must make sure all servers can reach each other on the network and that the web application URL is available from the Internet.
- What do you need to see/test to decide if the service is healthy?
In general, Contoso needs to see that the web site is available from the Internet. They also need to know that the application server can do SQL queries against the SQL Server. - What data do you need to collect to present what you need?
When talking about which data to collect, there are two different ways to look at monitoring, both business and technical.- Business Perspective is the perspective that the users of the service look at it. In this example, can users use web service from the Internet? The users don’t care if a hard disk is low on free space; they only care if they can access the web service and have a pleasant experience. For the business (or SLA) perspective, for this scenario, we only need to collect a URL check from the Internet.
- Technical Perspective is for the engineers operating and hosting the service. They care about all the small components of the service, everything that can affect the availability and performance of the service, for example, network connectivity, proactive SQL risks, server performance, events, log files, disk space, and so on.
- What are your reporting requirements?
For the Contoso web application, the reporting requirements are the number of requests on the web site and also web site availability per month. These should be delivered by e-mail to service owners at the beginning of each month, showing the previous month. - Where do you need to see your monitoring?
For example, Contoso needs to visualize the status in a dashboard and also get notification by e-mail if something is not working. There should also be integrated into the Contoso ITSM system to generate incidents if there is a critical error in the application. - Do you need to integrate into any other systems?
Contoso is running ServiceNow as the ITSM tool and wants to generate an incident if there are any errors. They are also using a SIEM tool to collect security events from different systems.
You should now have a clear scope of what you are going to monitor, the components in scope, how to visualize and report. The next step is to configure each component.
The “Cloud monitoring guide: Monitoring strategy for cloud deployment models” page will help you map your requirements to services in Azure.
What if we already have System Center Operations Manager (SCOM)?
If you already have System Center Operations Manager (SCOM) in place and it is working well, continue to use it, but add value with Azure services. SCOM has excellent capabilities, but it can be complicated to consolidate the information into easy to use dashboards. Azure Monitor also provides some additional capabilities that are not covered by SCOM today, such as tracking changes across your virtual machines or viewing the status of the updates.
The long-term vision can be to move all monitoring to native Azure services but review each monitoring requirements separately. For example, if you must collect and analyze security logs, for that Security Center and Azure Monitor is often a better solution than SCOM. If you take a structured approach to move each monitoring component separate to Azure Monitor as the capabilities match your requirements, one day it will all be in Azure. During the hybrid-monitoring, you will still fulfill all your monitoring requirements and use the best of both worlds for your monitoring solution. Â
Visualize Service Map data in Microsoft Visio
A common question in data center migration scenarios is dependencies between servers. Service Map can be very valuable in this scenario, visualizing TCP communication between processes on different servers.

Even if Service Map provides a great value we often hear a couple of questions, for example, visualize data for more than one hour and include more resources/servers in one image. Today this is not possible with the current feature set. But all the data needed is in the Log Analytics workspace, and we can access the data through the REST API 🙂
In this blog post, we want to show you how to visualize this data in Visio. We have built a PowerShell script that export data from the Log Analytics workspace and then builds a Visio drawing based on the information. The PowerShell script connects to Log Analytics, runs a query and saves the result in a text file. The query in our example lists all connections inbound and outbound for a server last week. The PowerShell script then reads the text file and for each connection, it draws it in the Visio file.
In the image below you see an example of the output in Visio. The example in the example we ran the script for a domain controller with a large number of connected servers, most likely more than the average server in a LOB application. In the example you can also see that for all connections to Azure services, we replace the server icon with a cloud icon.

Of course, you can use any query you want and visualize the data any way you want in Visio. Maybe you want to use different server shapes depending on communication type, or maybe you want to make some connections red if they have transferred a large about data.
In the PowerShell script, you can see that we use server_m.vssx and networklocations.vssx stencil files to find servers and cloud icons. These files and included in the Microsoft Visio installation. For more information about the PowerShell module used, please see VisioBot3000.
THE SOFTWARE IS PROVIDED “AS IS”, WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
From Service Map to Network Security Group
Many data center migration scenarios include moving from a central firewall to multiple smaller firewalls and network security groups. A common challenge is how to configure each network security group (NSG). What should be allowed?
One way to map out which traffic to allow is using Service Map, as shown in previous blog posts. It is also possible to take it one step further, by automatically reading Service Map data from Log Analytics and building NSG rules based on the collected data.
To show an example of this, we have put together a PowerShell script. The script reads Service Map data for a specific server and builds an NSG and NSG rules based on the read data. The NSG is then attached to the server’s network adapter. Download the script here.
Of course, there are some risks with this; for example, if there is an “evil process†running on the server and communicating on the network, then there will be an NSG rule for this too. Also, the Service Map will only collect data for TCP traffic, not UDP, and the script expects the server to already exist in Azure. You will not be able to use this script to create NSG rules for servers that have not been migrated.

Thanks to Vanessa for good conversation and ideas 🙂
Disclaimer: Cloud is a very fast-moving target. It means that by the time you’re reading this post, everything described here could have been changed completely. The blog post is provided “AS-IS†with no warranties.
Visualize Service Map data in a workbook
Service Map is a feature in Azure Monitor to automatically discovers communication between applications on both Windows and Linux servers. Service Map visualize collected data in a service map, with servers, processes, inbound and outbound connection latency, and ports across any TCP-connected architecture — more information about Service Map at Microsoft Docs.
The default Service Map view is very useful in many scenarios, but there is, from time to time, a need for creating custom views and reports based on the Service Map data. Custom views and reports are created with Kusto queries and workbooks. In this blog post, we will look at some examples of a visualize Service map data in a workbook.
One of the main reasons you may want to create customer workbooks based on Service Map data is that the default Service Map view only shows one hour of data, even if more data is collected.
Below is an image of Service Map, used in VM Insight. In the figure, you can see Windows server DC00 in the center and all processes on the server that communicates on the network. On the right side of the figure, we can see servers that DC00 communicates with, grouped on network ports. It is possible to select another server, for example, DC11, and see which process on DC11 communicating with the process on DC00.

All service map data is stored in two different tables, VMproccess and VMConnection. VMComputer has inventory data for servers. VMprocess has inventory data for TCP-connected processes on servers.
Here are a few sample queries to get you started.
To list all machines that have inbound communication on port 80 last week
VMConnection
| where DestinationPort == "80"
| where Direction == "inbound"
| where TimeGenerated > now(-7d)
| distinct Computer
To list unique processes on a virtual machine, for last week
VMProcess
| where Computer == "DC21.NA.contosohotels.com"
| where TimeGenerated > now(-7d)
| summarize arg_max(TimeGenerated, DisplayName, Description, Computer) by ExecutableName
To list all unique communication for a server, for last week
VMProcess |VMConnection | where Computer == "DC21.NA.contosohotels.com" | where TimeGenerated > now(-7d) | summarize arg_max(TimeGenerated, Computer, Direction, ProcessName) by RemoteIp, DestinationPort
To list all communication between two IP addresses
VMConnection
| where (SourceIp == "10.1.2.20" or SourceIp == "10.3.1.20") and (DestinationIp == "10.1.2.20" or DestinationIp == "10.3.1.20")
| where TimeGenerated > now(-7d)
| summarize arg_max(TimeGenerated, SourceIp, DestinationIp, Direction, ProcessName) by DestinationPort
With workbooks, you can create dynamic reports to visualize collected data. This is very useful in migration scenarios when building network traffic rules or needs to see dependencies between servers quickly. The picture below shows an example Workbook (download here) showing all traffic for a specific server and a summary (total MB) of network traffic per network port.

Return data only during office hours and workdays
Today I want to share a log query that only returns logs generated between 09 and 18, during workdays. The example is working with security events, without any filters. To improve query performances it is strongly recommended to add more filters, for example, event ID or account.
6.00:00:00 means Saturday and 7.00:00:00 means Sunday 🙂
let startDateOfAlert = startofday(now());
let StartAlertTime = startDateOfAlert + 9hours;
let StopAlertTime = startDateOfAlert + 18hours;
SecurityEvent
| extend localTimestamp = TimeGenerated + 2h
| extend ByPassDays = dayofweek(localTimestamp)
| where ByPassDays <> ‘6.00:00:00’
| where ByPassDays <> ‘7.00:00:00’
| where localTimestamp > StartAlertTime
| where localTimestamp < StopAlertTime
| order by localTimestamp asc
Visualize alerts on Azure dashboard [updated]
A common ask is how to visualize alerts from Azure Monitor on an Azure dashboard. Publishing data, including alerts, from Azure Monitor, can be accomplished with a workbook.
With Azure Monitor workbooks, we can create interactive reports based on collected data. Read more about Workbooks at Microsoft Docs.
In this example, we visualize new active alerts on an Azure Dashboard. We start with an empty workbook and add a query tile.

Configure the query, note that we use Alerts as data source and no summary of the result. We have also configured the query to show only New Fired alerts.

Use Column Settings to hide columns that should not be displayed.


Once we are happy with the look of the result, we can click PIN, and pin the panel to a dashboard. When in Edit mode of a tile, we can pin that specific tile. We can also use pin in the top toolbar to pin all parts of a workbook to a dashboard.

UPDATE
The suggested way to query for Azure Alert information is by using the * Azure Resource Graph data source, by querying the AlertsManagementResources table. See Azure Resource Graph table reference Azure Docs, or the Alerts template for examples. The Alerts data source will remain available for a period of time while authors transition to using ARG. Use of this data source in templates is discouraged.
See more at Microsoft Docs
Based on this new recommendation we should re-configure our workbook to use Azure Resource Graph as data source.

The query also needs to be a bit updated, as the image below. It is still the Kusto language, but the syntax is a bit different. To learn more about writing queries in Azure Resource Graph, see Microsoft Docs.

Columns can be renamed by using the column settings feature, see images below. Under column settings, you can also re-format date and configure thresholds on the severity, for example, a red warning sign for severity 0 alerts.



Monitoring Windows services with Azure Monitor
Another question we are asked regularly is how to use the Azure Monitor tools to create visibility on Windows service health. One of the best options for monitoring of services across Windows and Linux leverages off the Change Tracking solution in Azure Automation.
The solution can track changes on both Windows and Linux. On Windows, it supports tracking changes on files, registry keys, services, and installed software. On Linux, it tracks changes to files, software, and daemons. There are a couple of ways to onboard the solution, from a virtual machine, Automation account, or an Azure Automation runbook. Read more about Change tracking and how to onboard at Microsoft Docs.
This blog post will focus on monitoring of a Window service, but the concept works the same for Linux daemons.
Changes to Windows Services are collected by default every 30 minutes but can be configured to be collected down to every 10 seconds. It is important that the agent only track changes, not the current state. If there is no change, then there is no data sent to Log Analytics and Azure Automation. Collecting only changes optimizes the performance of the agent.

Query collected data
To list the latest collected data, we can run the following query. Note that we use “let†to set offset between UTC (default time zone in Log Analytics) and our current time zones. An important thing to remember is what we said earlier; only changes are reported. In the example below, we can see that at 2019-07-15 the service changed state to running. But after this record, we have no information. If the VM suddenly crashes, there is a risk no “Stopped†event will be reported, and from a logging perspective, it will look like the service is running.
It is therefore important to monitoring everything from a different point of views, for example, in this example also monitor the heartbeat from the VM.
let utcoffset = 2h; // difference between local time zone and UTC
ConfigurationData
| where ConfigDataType == "WindowsServices"
| where SvcDisplayName == "Print Spooler"
| extend localTimestamp = TimeGenerated + utcoffset
| project localTimestamp, Computer, SvcDisplayName, SvcState
| order by localTimestamp desc
| summarize arg_max(localTimestamp, *) by SvcDisplayName

Configure alert on service changes
As with other collected data, it is possible to configure an alert rule based on service changes. Below is a query that can be used to alert if the Print Spooler service is stopped. For more steps how to configure the alert, see Microsoft Docs.
ConfigurationChange
| where ConfigChangeType == "WindowsServices" and SvcDisplayName == "Print Spooler" and SvcState == "Stopped"

You may be tempted to use a query to look for Event 7036 in the Application log instead, but there are a few reasons why we would recommend you use the ConfigurationChange data instead:
- To be able to alert on Event 7036, you will need to collect informational level events from the Application log across all Windows servers, which becomes impractical very quickly when you have a larger number of Virtual Machines
- It requires more complex queries to alert on specific services
- It is only available on Windows servers
Workbook report
With Azure Monitor workbooks, we can create interactive reports based on collected data. Read more about Workbooks at Microsoft Docs.
For our service monitoring scenario, this is a great way to build a report of current status and a dashboard.
The following query can be used to list the latest event for each Windows service on each server. With the “case†operator, we can display 1 for running services and 0 for stopped services.
let utcoffset = 2h; // difference between local time zone and UTC
ConfigurationData
| where ConfigDataType == “WindowsServices”
| extend localTimestamp = TimeGenerated + utcoffset
| extend Status = case(SvcState == “Stopped”, “0”,
SvcState == “Running”, “1”,
“NA”
)
| project localTimestamp, Computer, SvcDisplayName, Status
| summarize arg_max(localTimestamp, *) by Computer, SvcDisplayName

1 and 0 can easily be used as thresholds in a workbook to colour set cells depending on status.

Workbooks can also be pinned to an Azure Dashboard, either all parts of a workbook or just some parts of it.

Recent Comments