Home » Log Analytics
Category Archives: Log Analytics
 Performance Reports and Groups
Performance Reports and Groups Highlight a couple of workbook features
Highlight a couple of workbook features AEM cross-forest
AEM cross-forestCustom availability monitoring
What if you need to monitor something that require a custom script? For example a sequence of checks? That is possible with a PowerShell script that do all the checks, and then submit the result to the workspace. In this example I will monitor port 25565 on a Minecraft server with a PowerShell script. Monitoring a network port is possible with the network insight feature, but it is still a good example as you can change the PowerShell script do do almost anything.
The first step was to create an Azure Automation runbook to check if the port is open. The runbook submit the result to Log Analytics through the data collector API.

A challenge with the runbook is schedules only allow it to run once per hour. To trigger the runbook more often, for example every five minutes, we can trigger it from a Logic Apps.

The PowerShell based runbook is now triggered to run every five minutes, sending its result to the Log Analytic workspace. Once the data is in the workspace, we can query it with a query, and for example show availability of the network port. As you can see on line six in the query, I have comment (for demo purpose) the line that shows only events from yesterday. The following blog post, Return data only during office hours and workdays , explains the query in details.
let totalevents = (24 * 12);
Custom_Port_CL
| extend localTimestamp = TimeGenerated + 2h
| where Port_s == "Minecraft Port"
| where Result_s == "Success"
// | where localTimestamp between (startofday(now(-1d)) .. endofday(now(-1d)) )
| summarize sum01 = count() by Port_s
| extend percentage = (todouble(sum01) * 100 / todouble(totalevents))
| project Port_s, percentage, events=sum01, possible_events=totalevents
The query will show percentage availability based on one event expected every five minutes.

Workbook Template
Today I want to share a workbook template that I often use. It has some basic parameters for subscription, tags, timeframe, VMs and workspace. The “services” parameter use tags to list virtual machines. For example if I select SAP from the services drop down, all virtual machines with a tag service set SAP will be visualized in the Virtual Machines drop down box.
The following images shows to the Service and Virtual Machines parameters are configured. The last image shows an example of using both Timeframe and Virtual Machines parameters in a Kusto query.
You can download the template in Gallery Template format here.



Compare the current counter value with previous one
Today I received a question about comparing a performance counter value with the previous performance counter value. In the example, we look at free space on C and compare the current value with the previous. As there are few examples in the community, I thought this would be a good example to share.
Perf
| where Computer == "idala"
| where CounterName == "% Free Space"
| where InstanceName == "C:"
| serialize | extend prevValue = prev(CounterValue, 1)
| extend diffvalue = CounterValue - prevValue
| extend trend = case(CounterValue < prevValue, "Free Space Reduces",
CounterValue > prevValue, "Free Space Increases",
"No difference")
| project TimeGenerated, InstanceName, CounterValue, prevValue, diffvalue, trend
| order by TimeGenerated desc First, we filter on a computer, counter name, and instance name. Before we can use Window functions on the result, we need to SERIALIZE it. SERIALIZE will freeze the result; in other words, freeze the order on the rows.
We use EXTEND to create a new column and assign it the value of the previous counterValue. “1” after CounterValue means we look on the 1 previous row; this is possible to do as we have a serialized set of rows.
We then use EXTEND to create a new column that will hold the difference (diffvalue) between the current counter value and the previous counter value.
Even if it is simple to see if the value has reduced or increased manually, we use CASE, and another EXTEND to write different text strings in a column depending on the current counter value and previous counter value.
Counting Devices
Today I would like to quickly share two queries. The first query counts number of devices that sent a heartbeat last month. The second query shows the number of devices sent heartbeat per month, for the current year.
let LastMonthEndDate = (startofmonth(now()) - 1h);
let LastMonthStartDate = startofmonth(LastMonthEndDate);
Heartbeat
| where TimeGenerated between(LastMonthStartDate .. (LastMonthEndDate))
| distinct Computer
| summarize ['Devices Last Month'] = count()
let YearStartDate = (startofyear(now()) - 1h);
Heartbeat
| where TimeGenerated between(YearStartDate .. (now()))
| extend Month = (datetime_part("month", TimeGenerated))
| summarize Devices = dcount(Computer) by Month

Trigger a runbook based on an Azure Monitor alert, and pass alert data to the runbook
Last week Vanessa and I worked on a scenario to trigger Azure automation based on Azure Monitor alerts. We notice the lack of documentation around this, so we thought we could share our settings. We will not go into recommended practices around trigger automation jobs for faster response and remediation. Still, we would recommend you read the Management Baseline chapter in the Cloud Adoption Framework, found here. Enhanced management baseline in Azure – Cloud Adoption Framework | Microsoft Docs. The chapter covers designing a management baseline for your organization and how to design enhancements, such as automatic alert remediation with Azure Automation.
The scenario is that a new user account is created in Active Directory. A data collection rule collects the audit event of the new user account. An alert rule triggers an alert based on the latest event and triggers an Azure Automation Runbook.
The blog post will show how to transfer data from the alert to the runbook, such as information about the new user account.
A new user account is created, named Sara Connor.

A security event is generated in the audit log.
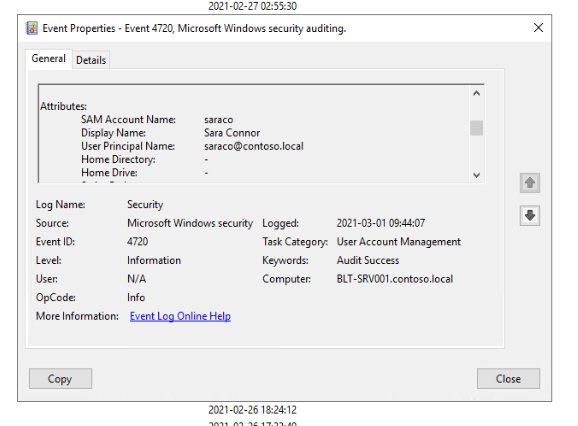
The event is collected and sent to Log Analytics by a data collection run.

An alert rule runs every five minutes to look for newly created accounts. The alert rule triggers the runbook. Note that the alert rule uses the Common Alert Schema to forward event information.



Information about the common alert schema at Microsoft Docs. Below is the query used in the alert rule, and the runbook code.
Event
| where EventLog == "Security"
| where EventID == "4720"
| parse EventData with * 'SamAccountName">' SamAccountName '' *
| parse EventData with * 'UserPrincipalName">' UserPrincipalName '' *
| parse EventData with * 'DisplayName">' DisplayName '' *
| project SamAccountName, DisplayName, UserPrincipalName
Runbook:
param
(
[Parameter (Mandatory=$false)]
[object] $WebhookData
)
# Collect properties of WebhookData.
$WebhookName = $WebhookData.WebhookName
$WebhookBody = $WebhookData.RequestBody
$WebhookHeaders = $WebhookData.RequestHeader
# Information on the webhook name that called This
Write-Output "This runbook was started from webhook $WebhookName."
# Obtain the WebhookBody containing the AlertContext
$WebhookBody = (ConvertFrom-Json -InputObject $WebhookBody)
Write-output "####### New User Created #########" -Verbos
Write-Output "Username: " $WebhookBody.data.alertContext.SearchResults.tables.rows[0] -Verbos
Write-Output "Display Name: " $WebhookBody.data.alertContext.SearchResults.tables.rows[1] -Verbos
Write-Output "User UPN: " $WebhookBody.data.alertContext.SearchResults.tables.rows[2] -Verbos
This is the output from the runbook, including details about the new user account.


Azure Monitor Data Ingestion Workbook
Last couple of weeks Vanessa and I have been working with analyzing costs for a Log Analytics workspace. As part of this work, we built a workbook, and of course, we want to share this workbook with the community
The idea with the workbook is to help identify the top data ingestion sources, especially around Computers, to help with optimizing the costs of using Azure Monitor. The workbook has two tabs, one to look at cost based on computer and one to look at cost by data type.



The “By computer†tab visualizes the total amount of ingested data by the server and the estimated data ingestion cost for this data. The price is calculated on a parameter where you input cost per GB. If you select a server, in this example dc01, another table will be visualized to show the amount of data, for each data type, for the selected server. For instance, in the screenshot, we can see that dc01 has ingested 1.13 GB performance data.
The second tab, “By data type†tab, visualize the total amount of ingested data by data type, and the estimated data ingestion cost for this data.
The “Azure Diagnostic” tab visualizes the total amount of ingested data by Azure Diagnostics, and the estimated data ingestion cost for this data.
The “Trends” tab compare data ingestion between two time periods. This tab visualize the ingestion difference between the two time periods and if the trend is decreased on increased.
The workbook is provided as a sample of what is possible. It does not replace current cost management tools or invoices from Microsoft. The costs in this workbook are estimated prices only and are not an official statement or invoice from Microsoft.
Download the workbook at GitHub.
Highlight a couple of workbook features
Workbooks provide a flexible canvas for data analysis and the creation of rich visual reports within the Azure portal. They allow you to tap into multiple data sources from across Azure and combine them into unified interactive experiences. Read more at the source, Microsoft Docs.
Vanessa and I have put together a workbook to visually report on computers missing updates. This can be done with Kusto queries in Log Analytics. Still, with workbooks, you can visualize it in a better way and make this visualization available to colleagues. It is also easier for someone without Kusto and Log Analytic knowledge to run a workbook.
In this example, we have to build a workbook that first lists all computers that are missing an update. We can see the computer name and the number of missing updates in the first view. If we select one of the servers, a new table is visualized, with detailed information for that computer, showing which updates that are missing. If we choose one of the updates, we get an additional table showing other computers missing the same update.



We would like to highlight some of the features used in the workbook that can be handy to know about when building workbooks.
To pass a value between queries inside the workbook, we can configure to export parameters per query item. This is set under Advanced Settings. In this example, the Computer column will be exported. To use this value in a query use {Computer}, for example
Update
| where TimeGenerated > now(-1d)
| where UpdateState == “Needed”
| where computer == “{Computer}”
| project TimeGenerated, Title, Classification, PublishedDate, Product, RebootBehavior, UpdateID
| sort by Product
Under Advanced Settings, you can also configure how to handle no data scenario. In this example, if no computers are missing updates, there will be a text saying, “Great! No servers missing updates!”.

Another handy setting is column settings. With column settings, you can, for example, rename a column in the workbook. In this example, we rename column “count_” to “# missing updates”.

The last feature we want to highlight is conditionally visible. Conditionally visible control when a query item is visible. In this example, the previous query item is not visualized until the user selects an update in the last query item. The UpdateID is exported as a parameter for the rest of the workbook.

Sharing dashboards and workbooks in the Azure Portal
Sharing dashboards and workbooks can be a bit tricky the first time.
A key thing to keep in mind when sharing workbooks and dashboards is that the user needs access to both the workbook or dashboard resource, and its data source.
Looking at the figure below, we have a dashboard named “Contoso Dashboard†that contains several tiles (colorful boxes). Each of these tiles has its data source (black cylinder). For example, the green tile can show recommendations for Active Directory. Active Directory assessment data comes from a table in the Log Analytics workspace.
The user of the “Contoso Dashboard†then needs access both to the dashboard itself and the Active Directory assessment data in the Log Analytics workspace.

Let’s do an example. In this example, we will share a dashboard and a workbook with a guest using a Microsoft account (contoso.guest@outlook.com). The Microsoft account is not a member of our Azure AD or have any other permissions in the Azure subscription.
Sharing Dashboards
First, we create a dashboard, with only a clock, and share it with the guest account.


The guest can now access the dashboard and see the clock. Essential to make sure the correct Azure AD directory is selected; else, the dashboard will not load in the Azure portal for the guest.
If we add two tiles from Log Analytics, we can see in the left part of the image below that the guest doesn’t have permission to load the Log Analytics data. On the right side of the image below, the portal is loaded with a contributor account.

Once we assign the guest Monitor Reader permissions on the Log Analytics workspace, the guest can load the tiles in the dashboard. The Monitor Reader gives the guest access to only monitoring data in the workspace.
Sharing Workbooks
If you pin tiles from a workbook to a dashboard, the guest doesn’t need to have access to the workbook itself, and the tile will still show data if the guest has access to the data source. If the guest clicks the tile, it is only the specific tile that will be loaded in a temporary workbook. In the example below, the guest only has access to data for one of the tiles.

It works very much the same as sharing dashboards. You need to share both data sources and the workbook resource itself. If you don’t share the workbook item itself, the following error might be shown.

Using only the “Share Report†feature at a workbook will not assign the necessary guest permissions, that must be done on the workbook resource item. In my examples I have used the Reader role on the workbook resource.

You can read more about the different role assignments for monitoring data here:
Scoping monitoring with Azure services
Introduction
Monitoring is key to all modern IT operations. It is the same if we are hosting all resources in a local data center or a public cloud. Looking back, we have used, for example, System Center Operations Manager for all applications and OS monitoring, then we often had one product to monitor our hardware and maybe one for our network. Even if the goal was to use one product, we often ended up with multiple ones without any connectivity between them.
In Azure, it will be a bit different from the beginning; we will already from the start use multiple services, and then connect them in the visualizing (dashboard) and reporting (workbook) layers. A significant difference compared to the local data center is that in Azure, all services and components are built to collaborate and work together. Another key difference compared with local datacentre is that in Azure, we quickly test new monitoring features, scale up and down, and immediately support the monitoring of new business services.
In this blog post, we will walk through how to get scope monitoring with Azure services. We will begin by setting the scope and expected outcome for the monitoring solution. Instead of saying we will monitor “everything,†we will create a scope based on what we need. Saying “we will monitor everything†often ends with an outdated, unnecessary complex solution that doesn’t fulfill our requirements and doesn’t give value.
Before starting setting the monitoring scope, we recommend you read the Introduction about Cloud monitoring guide in Microsoft Cloud Adoption Framework. Â
Setting the scope
To set the scope of monitoring, I often recommend to break it down per application, as it is applications that the business use, not hard disks or network segments. Often it is per application support case will be created, and the SLA is per business application. Once you have decided which application to focus on, ask the following questions;
- What is it that you need to monitor?
For example, let us say that Contoso has a web application, including a SQL Server database, an application server, and two web servers. Those components are what we need to monitor. All servers are running Windows Server 2012, and the database server is SQL 2012. There are two critical services on the application server and four Windows events to look for in the Event Viewer. All servers also need standard performance monitoring. We also must make sure all servers can reach each other on the network and that the web application URL is available from the Internet.
- What do you need to see/test to decide if the service is healthy?
In general, Contoso needs to see that the web site is available from the Internet. They also need to know that the application server can do SQL queries against the SQL Server. - What data do you need to collect to present what you need?
When talking about which data to collect, there are two different ways to look at monitoring, both business and technical.- Business Perspective is the perspective that the users of the service look at it. In this example, can users use web service from the Internet? The users don’t care if a hard disk is low on free space; they only care if they can access the web service and have a pleasant experience. For the business (or SLA) perspective, for this scenario, we only need to collect a URL check from the Internet.
- Technical Perspective is for the engineers operating and hosting the service. They care about all the small components of the service, everything that can affect the availability and performance of the service, for example, network connectivity, proactive SQL risks, server performance, events, log files, disk space, and so on.
- What are your reporting requirements?
For the Contoso web application, the reporting requirements are the number of requests on the web site and also web site availability per month. These should be delivered by e-mail to service owners at the beginning of each month, showing the previous month. - Where do you need to see your monitoring?
For example, Contoso needs to visualize the status in a dashboard and also get notification by e-mail if something is not working. There should also be integrated into the Contoso ITSM system to generate incidents if there is a critical error in the application. - Do you need to integrate into any other systems?
Contoso is running ServiceNow as the ITSM tool and wants to generate an incident if there are any errors. They are also using a SIEM tool to collect security events from different systems.
You should now have a clear scope of what you are going to monitor, the components in scope, how to visualize and report. The next step is to configure each component.
The “Cloud monitoring guide: Monitoring strategy for cloud deployment models” page will help you map your requirements to services in Azure.
What if we already have System Center Operations Manager (SCOM)?
If you already have System Center Operations Manager (SCOM) in place and it is working well, continue to use it, but add value with Azure services. SCOM has excellent capabilities, but it can be complicated to consolidate the information into easy to use dashboards. Azure Monitor also provides some additional capabilities that are not covered by SCOM today, such as tracking changes across your virtual machines or viewing the status of the updates.
The long-term vision can be to move all monitoring to native Azure services but review each monitoring requirements separately. For example, if you must collect and analyze security logs, for that Security Center and Azure Monitor is often a better solution than SCOM. If you take a structured approach to move each monitoring component separate to Azure Monitor as the capabilities match your requirements, one day it will all be in Azure. During the hybrid-monitoring, you will still fulfill all your monitoring requirements and use the best of both worlds for your monitoring solution. Â
Visualize Service Map data in Microsoft Visio
A common question in data center migration scenarios is dependencies between servers. Service Map can be very valuable in this scenario, visualizing TCP communication between processes on different servers.

Even if Service Map provides a great value we often hear a couple of questions, for example, visualize data for more than one hour and include more resources/servers in one image. Today this is not possible with the current feature set. But all the data needed is in the Log Analytics workspace, and we can access the data through the REST API 🙂
In this blog post, we want to show you how to visualize this data in Visio. We have built a PowerShell script that export data from the Log Analytics workspace and then builds a Visio drawing based on the information. The PowerShell script connects to Log Analytics, runs a query and saves the result in a text file. The query in our example lists all connections inbound and outbound for a server last week. The PowerShell script then reads the text file and for each connection, it draws it in the Visio file.
In the image below you see an example of the output in Visio. The example in the example we ran the script for a domain controller with a large number of connected servers, most likely more than the average server in a LOB application. In the example you can also see that for all connections to Azure services, we replace the server icon with a cloud icon.

Of course, you can use any query you want and visualize the data any way you want in Visio. Maybe you want to use different server shapes depending on communication type, or maybe you want to make some connections red if they have transferred a large about data.
In the PowerShell script, you can see that we use server_m.vssx and networklocations.vssx stencil files to find servers and cloud icons. These files and included in the Microsoft Visio installation. For more information about the PowerShell module used, please see VisioBot3000.
THE SOFTWARE IS PROVIDED “AS IS”, WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
Recent Comments