Home » Posts tagged 'Log Analytics'
Tag Archives: Log Analytics
Custom availability monitoring
What if you need to monitor something that require a custom script? For example a sequence of checks? That is possible with a PowerShell script that do all the checks, and then submit the result to the workspace. In this example I will monitor port 25565 on a Minecraft server with a PowerShell script. Monitoring a network port is possible with the network insight feature, but it is still a good example as you can change the PowerShell script do do almost anything.
The first step was to create an Azure Automation runbook to check if the port is open. The runbook submit the result to Log Analytics through the data collector API.

A challenge with the runbook is schedules only allow it to run once per hour. To trigger the runbook more often, for example every five minutes, we can trigger it from a Logic Apps.

The PowerShell based runbook is now triggered to run every five minutes, sending its result to the Log Analytic workspace. Once the data is in the workspace, we can query it with a query, and for example show availability of the network port. As you can see on line six in the query, I have comment (for demo purpose) the line that shows only events from yesterday. The following blog post, Return data only during office hours and workdays , explains the query in details.
let totalevents = (24 * 12);
Custom_Port_CL
| extend localTimestamp = TimeGenerated + 2h
| where Port_s == "Minecraft Port"
| where Result_s == "Success"
// | where localTimestamp between (startofday(now(-1d)) .. endofday(now(-1d)) )
| summarize sum01 = count() by Port_s
| extend percentage = (todouble(sum01) * 100 / todouble(totalevents))
| project Port_s, percentage, events=sum01, possible_events=totalevents
The query will show percentage availability based on one event expected every five minutes.

% Free Space for Linux and Windows servers
In the workbook published yesterday we used one graph for %Used Space from Linux servers, and one graph for %Free Space from Windows servers. But for some scenarios you might want to show disk space from both server types in the same graph. The following query convert Linux %Used Space to %Free Space, so they can be visualized together with %Free Space with data from Windows servers.
Perf
| where TimeGenerated between (ago(1d) .. now() )
| where CounterName == "% Used Space" or CounterName == "% Free Space"
| where InstanceName != "_Total"
| where InstanceName !contains "HarddiskVolume"
| extend FreeSpace = iff(CounterName == "% Used Space", 100-CounterValue, CounterValue)
| extend localTimestamp = TimeGenerated + 2h
| extend description = strcat(Computer, " ", InstanceName)
| summarize avg(FreeSpace) by bin(localTimestamp, 10m), description
| sort by localTimestamp desc
| render timechart Thanks to Vanessa for good conversation and ideas 🙂
Workbook Template
Today I want to share a workbook template that I often use. It has some basic parameters for subscription, tags, timeframe, VMs and workspace. The “services” parameter use tags to list virtual machines. For example if I select SAP from the services drop down, all virtual machines with a tag service set SAP will be visualized in the Virtual Machines drop down box.
The following images shows to the Service and Virtual Machines parameters are configured. The last image shows an example of using both Timeframe and Virtual Machines parameters in a Kusto query.
You can download the template in Gallery Template format here.



Compare the current counter value with previous one
Today I received a question about comparing a performance counter value with the previous performance counter value. In the example, we look at free space on C and compare the current value with the previous. As there are few examples in the community, I thought this would be a good example to share.
Perf
| where Computer == "idala"
| where CounterName == "% Free Space"
| where InstanceName == "C:"
| serialize | extend prevValue = prev(CounterValue, 1)
| extend diffvalue = CounterValue - prevValue
| extend trend = case(CounterValue < prevValue, "Free Space Reduces",
CounterValue > prevValue, "Free Space Increases",
"No difference")
| project TimeGenerated, InstanceName, CounterValue, prevValue, diffvalue, trend
| order by TimeGenerated desc First, we filter on a computer, counter name, and instance name. Before we can use Window functions on the result, we need to SERIALIZE it. SERIALIZE will freeze the result; in other words, freeze the order on the rows.
We use EXTEND to create a new column and assign it the value of the previous counterValue. “1” after CounterValue means we look on the 1 previous row; this is possible to do as we have a serialized set of rows.
We then use EXTEND to create a new column that will hold the difference (diffvalue) between the current counter value and the previous counter value.
Even if it is simple to see if the value has reduced or increased manually, we use CASE, and another EXTEND to write different text strings in a column depending on the current counter value and previous counter value.
Counting Devices
Today I would like to quickly share two queries. The first query counts number of devices that sent a heartbeat last month. The second query shows the number of devices sent heartbeat per month, for the current year.
let LastMonthEndDate = (startofmonth(now()) - 1h);
let LastMonthStartDate = startofmonth(LastMonthEndDate);
Heartbeat
| where TimeGenerated between(LastMonthStartDate .. (LastMonthEndDate))
| distinct Computer
| summarize ['Devices Last Month'] = count()
let YearStartDate = (startofyear(now()) - 1h);
Heartbeat
| where TimeGenerated between(YearStartDate .. (now()))
| extend Month = (datetime_part("month", TimeGenerated))
| summarize Devices = dcount(Computer) by Month

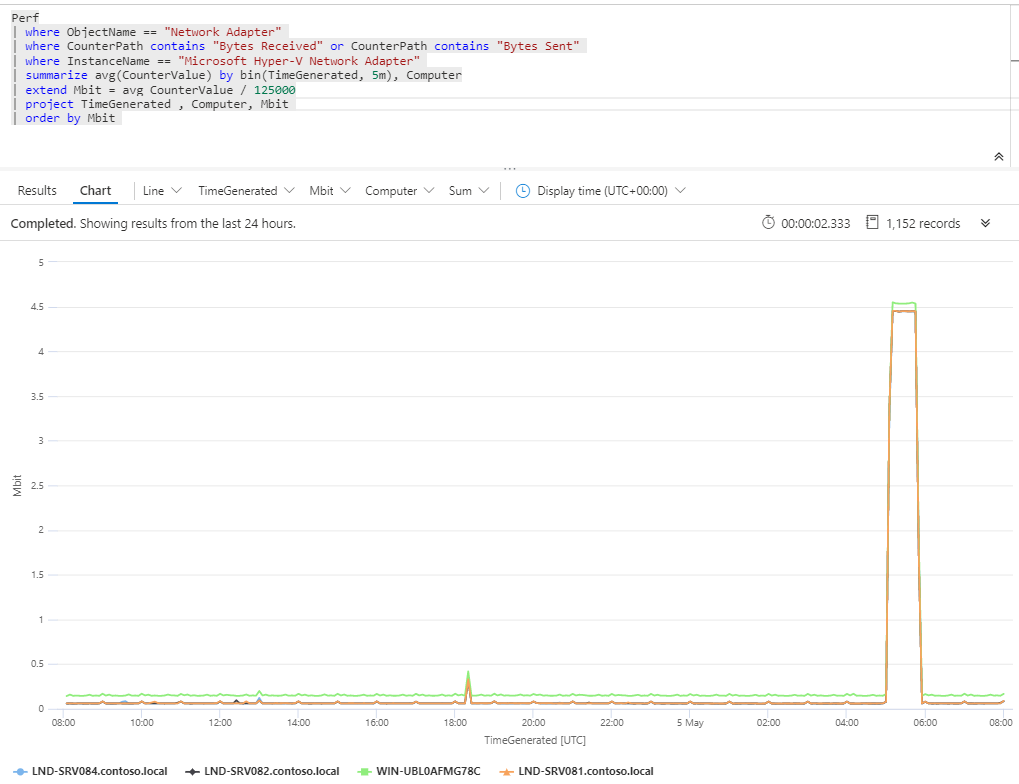
Measure bandwidth with Azure Monitor
Today I want to quickly share a query that shows Mbit used for a specific network adapter.
Perf
| where ObjectName == “Network Adapter”
| where Computer == “DC20.NA.contosohotels.com”
| where CounterPath contains “Bytes Received” or CounterPath contains “Bytes Sent”
| where InstanceName == “Microsoft Hyper-V Network Adapter”
| summarize avg(CounterValue) by bin(TimeGenerated, 5m)
| extend Mbit = avg_CounterValue / 125000
| project TimeGenerated , Mbit
This query can, for example, be used in migration scenarios to estimate network connection required. The query will convert bytes to Mbit.
Return data only during office hours and workdays
Today I want to share a log query that only returns logs generated between 09 and 18, during workdays. The example is working with security events, without any filters. To improve query performances it is strongly recommended to add more filters, for example, event ID or account.
6.00:00:00 means Saturday and 7.00:00:00 means Sunday 🙂
let startDateOfAlert = startofday(now());
let StartAlertTime = startDateOfAlert + 9hours;
let StopAlertTime = startDateOfAlert + 18hours;
SecurityEvent
| extend localTimestamp = TimeGenerated + 2h
| extend ByPassDays = dayofweek(localTimestamp)
| where ByPassDays <> ‘6.00:00:00’
| where ByPassDays <> ‘7.00:00:00’
| where localTimestamp > StartAlertTime
| where localTimestamp < StopAlertTime
| order by localTimestamp asc
Monitoring Windows services with Azure Monitor
Another question we are asked regularly is how to use the Azure Monitor tools to create visibility on Windows service health. One of the best options for monitoring of services across Windows and Linux leverages off the Change Tracking solution in Azure Automation.
The solution can track changes on both Windows and Linux. On Windows, it supports tracking changes on files, registry keys, services, and installed software. On Linux, it tracks changes to files, software, and daemons. There are a couple of ways to onboard the solution, from a virtual machine, Automation account, or an Azure Automation runbook. Read more about Change tracking and how to onboard at Microsoft Docs.
This blog post will focus on monitoring of a Window service, but the concept works the same for Linux daemons.
Changes to Windows Services are collected by default every 30 minutes but can be configured to be collected down to every 10 seconds. It is important that the agent only track changes, not the current state. If there is no change, then there is no data sent to Log Analytics and Azure Automation. Collecting only changes optimizes the performance of the agent.

Query collected data
To list the latest collected data, we can run the following query. Note that we use “let†to set offset between UTC (default time zone in Log Analytics) and our current time zones. An important thing to remember is what we said earlier; only changes are reported. In the example below, we can see that at 2019-07-15 the service changed state to running. But after this record, we have no information. If the VM suddenly crashes, there is a risk no “Stopped†event will be reported, and from a logging perspective, it will look like the service is running.
It is therefore important to monitoring everything from a different point of views, for example, in this example also monitor the heartbeat from the VM.
let utcoffset = 2h; // difference between local time zone and UTC
ConfigurationData
| where ConfigDataType == "WindowsServices"
| where SvcDisplayName == "Print Spooler"
| extend localTimestamp = TimeGenerated + utcoffset
| project localTimestamp, Computer, SvcDisplayName, SvcState
| order by localTimestamp desc
| summarize arg_max(localTimestamp, *) by SvcDisplayName

Configure alert on service changes
As with other collected data, it is possible to configure an alert rule based on service changes. Below is a query that can be used to alert if the Print Spooler service is stopped. For more steps how to configure the alert, see Microsoft Docs.
ConfigurationChange
| where ConfigChangeType == "WindowsServices" and SvcDisplayName == "Print Spooler" and SvcState == "Stopped"

You may be tempted to use a query to look for Event 7036 in the Application log instead, but there are a few reasons why we would recommend you use the ConfigurationChange data instead:
- To be able to alert on Event 7036, you will need to collect informational level events from the Application log across all Windows servers, which becomes impractical very quickly when you have a larger number of Virtual Machines
- It requires more complex queries to alert on specific services
- It is only available on Windows servers
Workbook report
With Azure Monitor workbooks, we can create interactive reports based on collected data. Read more about Workbooks at Microsoft Docs.
For our service monitoring scenario, this is a great way to build a report of current status and a dashboard.
The following query can be used to list the latest event for each Windows service on each server. With the “case†operator, we can display 1 for running services and 0 for stopped services.
let utcoffset = 2h; // difference between local time zone and UTC
ConfigurationData
| where ConfigDataType == “WindowsServices”
| extend localTimestamp = TimeGenerated + utcoffset
| extend Status = case(SvcState == “Stopped”, “0”,
SvcState == “Running”, “1”,
“NA”
)
| project localTimestamp, Computer, SvcDisplayName, Status
| summarize arg_max(localTimestamp, *) by Computer, SvcDisplayName

1 and 0 can easily be used as thresholds in a workbook to colour set cells depending on status.

Workbooks can also be pinned to an Azure Dashboard, either all parts of a workbook or just some parts of it.

Setting up heartbeat failure alerts with Azure Monitor
One of the questions we receive regularly is how to use the Azure Monitor components to alert on machines that are not available, and then how to create availability reports using these tools.
My colleague Vanessa and I have been looking at the best ways of achieving this in a way that those who are migrating from tools like System Center Operations Manager would be familiar and comfortable with.
As the monitoring agent used by Azure Monitor on both Windows and Linux sends a heartbeat every minute, the easiest method to detect a server down event, regardless of server location, would be to alert on missing heartbeats. This means you can use one alert rule to notify for heartbeat failures, even if machines are hosted on-prem.
Log Ingestion Time and Latency
Before we look at the technical detail, it is worth calling out the Log Ingestion Time for Azure Monitor. This is particularly important if you are expecting heartbeat missed notifications within a specific time frame. In the Log Ingestion Time article, the following query is shared, which you can use to view the computers with the highest ingestion time over the last 8 hours. This can help you plan out the thresholds for the alerting settings.
Heartbeat | where TimeGenerated > ago(8h) | extend E2EIngestionLatency = ingestion_time() - TimeGenerated | summarize percentiles(E2EIngestionLatency,50,95) by Computer | top 20 by percentile_E2EIngestionLatency_95 desc
Alerting
You can use the following query in Logs to retrieve machines that have not sent a heartbeat in the last 5 minutes:Heartbeat
| summarize LastHeartbeat=max(TimeGenerated) by Computer
| where LastHeartbeat < ago(5m)
The query, based on Heartbeat, is good for reporting and dashboarding, but often using the Heartbeat Metric in the alert rule fields gives faster results. Read more about Metrics here. To create an alert rule based on metrics, you want to target the Workspace resource still, but, in the condition, you want to use the Heartbeat metric signal:

You will now be able to configure the alert options.

- Select the computers to alert on. You can choose Select All
- Change to Less or equal to, and enter 0 as your threshold value
- Select your aggregation granularity and frequency
The best results we have found during testing is an alert within two minutes of a machine shut down, with the above settings – keeping the ingestion and latency in mind.
Using these settings, you should get an alert for each unavailable machine within a few minutes after it becomes unavailable. But, as the signal relies on the heartbeat of the agent, this may also alert during maintenance times, or if the agent is stopped.
If you need an alert quickly, and you are not concerned with an alert flood, then use these settings.
However, if you want to ensure that you only alert on valid server outages, you may want to take a few additional steps. You can use Azure Automation Runbooks or Logic Apps as an alert response to perform some additional diagnostic steps, and trigger another alert based on the output. This could replicate the method used in SCOM with a Heartbeat Failure alert and a Failed to Connect alert.
If you are only monitoring Azure Hosted virtual machines, you could also use the Activity Log to look for Server Shutdown events, using the following query:AzureActivity
| where OperationName == "Deallocate Virtual Machine" and ActivityStatus == "Succeeded"
| where TimeGenerated > ago(5m)
Reporting
Conversations about server unavailable alerts invariably lead to questions around the ability to report on Server Update/Availability. In the Logs blade, there are a few sample queries available relating to availability:

With the availability rate query by default returning the availability for monitored virtual machines for the last hour, but also providing you with an availability rate query that you can build on. This can be updated to show the availability for the last 30 days as follows:
let start_time=startofday(now()-30d);
let end_time=now();
Heartbeat
| where TimeGenerated > start_time and TimeGenerated < end_time | summarize heartbeat_per_hour=count() by bin_at(TimeGenerated, 1h, start_time), Computer | extend available_per_hour=iff(heartbeat_per_hour>0, true, false)
| summarize total_available_hours=countif(available_per_hour==true) by Computer
| extend total_number_of_buckets=round((end_time-start_time)/1h)+1
| extend availability_rate=total_available_hours*100/total_number_of_buckets
Or, if you are storing more than one month of data, you can also modify the query to run for the previous month:
let start_time=startofmonth(datetime_add('month',-1,now()));
let end_time=endofmonth(datetime_add('month',-1,now()));
Heartbeat
| where TimeGenerated > start_time and TimeGenerated < end_time
| summarize heartbeat_per_hour=count() by bin_at(TimeGenerated, 5m, start_time), Computer | extend available_per_hour=iff(heartbeat_per_hour>0, true, false)
| summarize total_available_hours=countif(available_per_hour==true) by Computer
| extend total_number_of_buckets=round((end_time-start_time)/5m)+1
| extend availability_rate=total_available_hours*100/total_number_of_buckets
These queries can be used in a Workbook to create an availability report

Note that the availability report is based on heartbeats, not the actual service running on the server. For example, if multiple servers are part of an availability set or a cluster, the service might still be available even if one server is unavailable.
Further reading
- Manage Metric Alerts
- Metric Alerts on Logs
- Agent Health Solution
- Using Azure Automation to take action on Azure Alerts
- Implement a Logic App action on an Alert
- Create Interactive Reports using Workbooks
Disclaimer: Cloud is a very fast-moving target. It means that by the time you’re reading this post, everything described here could have been changed completely. The blog post is provided “AS-IS†with no warranties.
Recent Comments