Home » Posts tagged 'Kusto Query'
Tag Archives: Kusto Query
 Custom AEM Report
Custom AEM Report R2, Gateway server and a SUSE machine
R2, Gateway server and a SUSE machineShow number of hours a computer has been sending heartbeats, per day
Today I needed a Kusto query to show number of heartbeat events per computer, per day, for the last week. The query also needed to estimate number of hours based on the amount of heartbeat events. The query is similar to the query in the Return data only during office hours and workdays post.
Heartbeat
| where Computer == "ninja-linux" or Computer == "WORKSTATION13"
| where TimeGenerated >= startofday(ago(7d))
| summarize minutes = count() by bin(TimeGenerated, 1d), Computer
| project Date = format_datetime(TimeGenerated, 'dd-MM'), Computer, WeekDay = case(
dayofweek(TimeGenerated) == "1:00:00:00", "Mo",
dayofweek(TimeGenerated) == "2:00:00:00", "Tu",
dayofweek(TimeGenerated) == "3:00:00:00", "We",
dayofweek(TimeGenerated) == "4:00:00:00", "Th",
dayofweek(TimeGenerated) == "5:00:00:00", "Fr",
dayofweek(TimeGenerated) == "6:00:00:00", "Sa",
dayofweek(TimeGenerated) == "0:00:00:00", "Su",
"Unknown day"), Hours = minutes / 60, Events = minutes
| order by Date

Custom availability monitoring
What if you need to monitor something that require a custom script? For example a sequence of checks? That is possible with a PowerShell script that do all the checks, and then submit the result to the workspace. In this example I will monitor port 25565 on a Minecraft server with a PowerShell script. Monitoring a network port is possible with the network insight feature, but it is still a good example as you can change the PowerShell script do do almost anything.
The first step was to create an Azure Automation runbook to check if the port is open. The runbook submit the result to Log Analytics through the data collector API.

A challenge with the runbook is schedules only allow it to run once per hour. To trigger the runbook more often, for example every five minutes, we can trigger it from a Logic Apps.

The PowerShell based runbook is now triggered to run every five minutes, sending its result to the Log Analytic workspace. Once the data is in the workspace, we can query it with a query, and for example show availability of the network port. As you can see on line six in the query, I have comment (for demo purpose) the line that shows only events from yesterday. The following blog post, Return data only during office hours and workdays , explains the query in details.
let totalevents = (24 * 12);
Custom_Port_CL
| extend localTimestamp = TimeGenerated + 2h
| where Port_s == "Minecraft Port"
| where Result_s == "Success"
// | where localTimestamp between (startofday(now(-1d)) .. endofday(now(-1d)) )
| summarize sum01 = count() by Port_s
| extend percentage = (todouble(sum01) * 100 / todouble(totalevents))
| project Port_s, percentage, events=sum01, possible_events=totalevents
The query will show percentage availability based on one event expected every five minutes.

% Free Space for Linux and Windows servers
In the workbook published yesterday we used one graph for %Used Space from Linux servers, and one graph for %Free Space from Windows servers. But for some scenarios you might want to show disk space from both server types in the same graph. The following query convert Linux %Used Space to %Free Space, so they can be visualized together with %Free Space with data from Windows servers.
Perf
| where TimeGenerated between (ago(1d) .. now() )
| where CounterName == "% Used Space" or CounterName == "% Free Space"
| where InstanceName != "_Total"
| where InstanceName !contains "HarddiskVolume"
| extend FreeSpace = iff(CounterName == "% Used Space", 100-CounterValue, CounterValue)
| extend localTimestamp = TimeGenerated + 2h
| extend description = strcat(Computer, " ", InstanceName)
| summarize avg(FreeSpace) by bin(localTimestamp, 10m), description
| sort by localTimestamp desc
| render timechart Thanks to Vanessa for good conversation and ideas 🙂
Compare the current counter value with previous one
Today I received a question about comparing a performance counter value with the previous performance counter value. In the example, we look at free space on C and compare the current value with the previous. As there are few examples in the community, I thought this would be a good example to share.
Perf
| where Computer == "idala"
| where CounterName == "% Free Space"
| where InstanceName == "C:"
| serialize | extend prevValue = prev(CounterValue, 1)
| extend diffvalue = CounterValue - prevValue
| extend trend = case(CounterValue < prevValue, "Free Space Reduces",
CounterValue > prevValue, "Free Space Increases",
"No difference")
| project TimeGenerated, InstanceName, CounterValue, prevValue, diffvalue, trend
| order by TimeGenerated desc First, we filter on a computer, counter name, and instance name. Before we can use Window functions on the result, we need to SERIALIZE it. SERIALIZE will freeze the result; in other words, freeze the order on the rows.
We use EXTEND to create a new column and assign it the value of the previous counterValue. “1” after CounterValue means we look on the 1 previous row; this is possible to do as we have a serialized set of rows.
We then use EXTEND to create a new column that will hold the difference (diffvalue) between the current counter value and the previous counter value.
Even if it is simple to see if the value has reduced or increased manually, we use CASE, and another EXTEND to write different text strings in a column depending on the current counter value and previous counter value.
Counting Devices
Today I would like to quickly share two queries. The first query counts number of devices that sent a heartbeat last month. The second query shows the number of devices sent heartbeat per month, for the current year.
let LastMonthEndDate = (startofmonth(now()) - 1h);
let LastMonthStartDate = startofmonth(LastMonthEndDate);
Heartbeat
| where TimeGenerated between(LastMonthStartDate .. (LastMonthEndDate))
| distinct Computer
| summarize ['Devices Last Month'] = count()
let YearStartDate = (startofyear(now()) - 1h);
Heartbeat
| where TimeGenerated between(YearStartDate .. (now()))
| extend Month = (datetime_part("month", TimeGenerated))
| summarize Devices = dcount(Computer) by Month

Highlight a couple of workbook features
Workbooks provide a flexible canvas for data analysis and the creation of rich visual reports within the Azure portal. They allow you to tap into multiple data sources from across Azure and combine them into unified interactive experiences. Read more at the source, Microsoft Docs.
Vanessa and I have put together a workbook to visually report on computers missing updates. This can be done with Kusto queries in Log Analytics. Still, with workbooks, you can visualize it in a better way and make this visualization available to colleagues. It is also easier for someone without Kusto and Log Analytic knowledge to run a workbook.
In this example, we have to build a workbook that first lists all computers that are missing an update. We can see the computer name and the number of missing updates in the first view. If we select one of the servers, a new table is visualized, with detailed information for that computer, showing which updates that are missing. If we choose one of the updates, we get an additional table showing other computers missing the same update.



We would like to highlight some of the features used in the workbook that can be handy to know about when building workbooks.
To pass a value between queries inside the workbook, we can configure to export parameters per query item. This is set under Advanced Settings. In this example, the Computer column will be exported. To use this value in a query use {Computer}, for example
Update
| where TimeGenerated > now(-1d)
| where UpdateState == “Needed”
| where computer == “{Computer}”
| project TimeGenerated, Title, Classification, PublishedDate, Product, RebootBehavior, UpdateID
| sort by Product
Under Advanced Settings, you can also configure how to handle no data scenario. In this example, if no computers are missing updates, there will be a text saying, “Great! No servers missing updates!”.

Another handy setting is column settings. With column settings, you can, for example, rename a column in the workbook. In this example, we rename column “count_” to “# missing updates”.

The last feature we want to highlight is conditionally visible. Conditionally visible control when a query item is visible. In this example, the previous query item is not visualized until the user selects an update in the last query item. The UpdateID is exported as a parameter for the rest of the workbook.

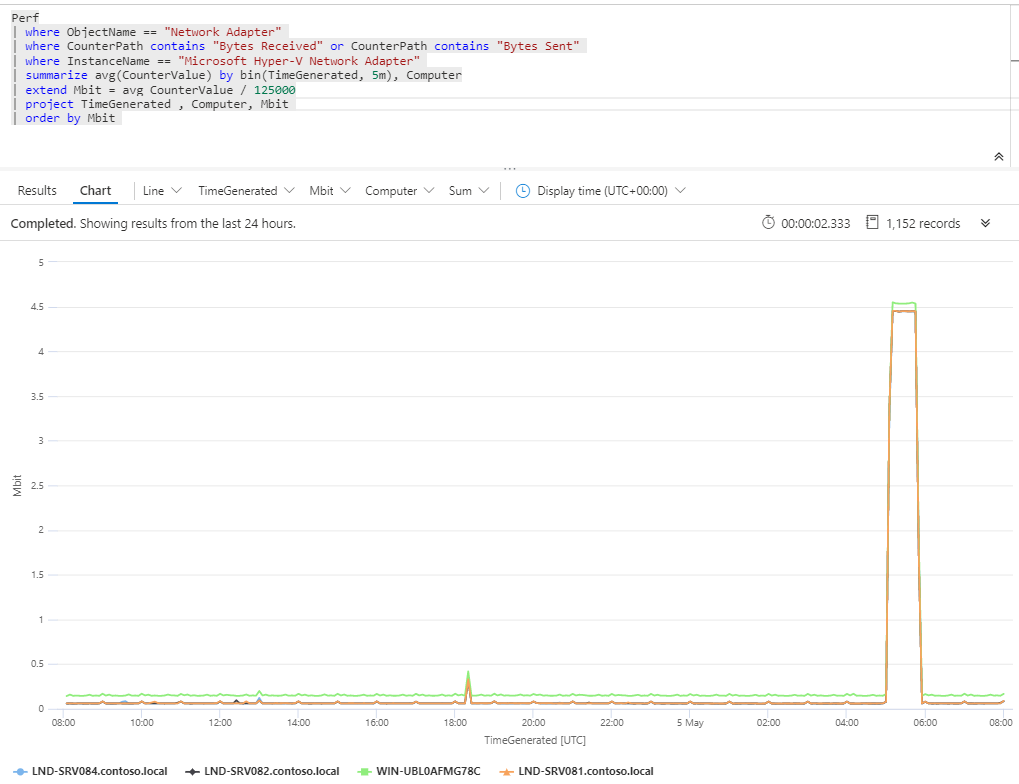
Measure bandwidth with Azure Monitor
Today I want to quickly share a query that shows Mbit used for a specific network adapter.
Perf
| where ObjectName == “Network Adapter”
| where Computer == “DC20.NA.contosohotels.com”
| where CounterPath contains “Bytes Received” or CounterPath contains “Bytes Sent”
| where InstanceName == “Microsoft Hyper-V Network Adapter”
| summarize avg(CounterValue) by bin(TimeGenerated, 5m)
| extend Mbit = avg_CounterValue / 125000
| project TimeGenerated , Mbit
This query can, for example, be used in migration scenarios to estimate network connection required. The query will convert bytes to Mbit.
Visualize Service Map data in Microsoft Visio
A common question in data center migration scenarios is dependencies between servers. Service Map can be very valuable in this scenario, visualizing TCP communication between processes on different servers.

Even if Service Map provides a great value we often hear a couple of questions, for example, visualize data for more than one hour and include more resources/servers in one image. Today this is not possible with the current feature set. But all the data needed is in the Log Analytics workspace, and we can access the data through the REST API 🙂
In this blog post, we want to show you how to visualize this data in Visio. We have built a PowerShell script that export data from the Log Analytics workspace and then builds a Visio drawing based on the information. The PowerShell script connects to Log Analytics, runs a query and saves the result in a text file. The query in our example lists all connections inbound and outbound for a server last week. The PowerShell script then reads the text file and for each connection, it draws it in the Visio file.
In the image below you see an example of the output in Visio. The example in the example we ran the script for a domain controller with a large number of connected servers, most likely more than the average server in a LOB application. In the example you can also see that for all connections to Azure services, we replace the server icon with a cloud icon.

Of course, you can use any query you want and visualize the data any way you want in Visio. Maybe you want to use different server shapes depending on communication type, or maybe you want to make some connections red if they have transferred a large about data.
In the PowerShell script, you can see that we use server_m.vssx and networklocations.vssx stencil files to find servers and cloud icons. These files and included in the Microsoft Visio installation. For more information about the PowerShell module used, please see VisioBot3000.
THE SOFTWARE IS PROVIDED “AS IS”, WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
Visualize Service Map data in a workbook
Service Map is a feature in Azure Monitor to automatically discovers communication between applications on both Windows and Linux servers. Service Map visualize collected data in a service map, with servers, processes, inbound and outbound connection latency, and ports across any TCP-connected architecture — more information about Service Map at Microsoft Docs.
The default Service Map view is very useful in many scenarios, but there is, from time to time, a need for creating custom views and reports based on the Service Map data. Custom views and reports are created with Kusto queries and workbooks. In this blog post, we will look at some examples of a visualize Service map data in a workbook.
One of the main reasons you may want to create customer workbooks based on Service Map data is that the default Service Map view only shows one hour of data, even if more data is collected.
Below is an image of Service Map, used in VM Insight. In the figure, you can see Windows server DC00 in the center and all processes on the server that communicates on the network. On the right side of the figure, we can see servers that DC00 communicates with, grouped on network ports. It is possible to select another server, for example, DC11, and see which process on DC11 communicating with the process on DC00.

All service map data is stored in two different tables, VMproccess and VMConnection. VMComputer has inventory data for servers. VMprocess has inventory data for TCP-connected processes on servers.
Here are a few sample queries to get you started.
To list all machines that have inbound communication on port 80 last week
VMConnection
| where DestinationPort == "80"
| where Direction == "inbound"
| where TimeGenerated > now(-7d)
| distinct Computer
To list unique processes on a virtual machine, for last week
VMProcess
| where Computer == "DC21.NA.contosohotels.com"
| where TimeGenerated > now(-7d)
| summarize arg_max(TimeGenerated, DisplayName, Description, Computer) by ExecutableName
To list all unique communication for a server, for last week
VMProcess |VMConnection | where Computer == "DC21.NA.contosohotels.com" | where TimeGenerated > now(-7d) | summarize arg_max(TimeGenerated, Computer, Direction, ProcessName) by RemoteIp, DestinationPort
To list all communication between two IP addresses
VMConnection
| where (SourceIp == "10.1.2.20" or SourceIp == "10.3.1.20") and (DestinationIp == "10.1.2.20" or DestinationIp == "10.3.1.20")
| where TimeGenerated > now(-7d)
| summarize arg_max(TimeGenerated, SourceIp, DestinationIp, Direction, ProcessName) by DestinationPort
With workbooks, you can create dynamic reports to visualize collected data. This is very useful in migration scenarios when building network traffic rules or needs to see dependencies between servers quickly. The picture below shows an example Workbook (download here) showing all traffic for a specific server and a summary (total MB) of network traffic per network port.

Return data only during office hours and workdays
Today I want to share a log query that only returns logs generated between 09 and 18, during workdays. The example is working with security events, without any filters. To improve query performances it is strongly recommended to add more filters, for example, event ID or account.
6.00:00:00 means Saturday and 7.00:00:00 means Sunday 🙂
let startDateOfAlert = startofday(now());
let StartAlertTime = startDateOfAlert + 9hours;
let StopAlertTime = startDateOfAlert + 18hours;
SecurityEvent
| extend localTimestamp = TimeGenerated + 2h
| extend ByPassDays = dayofweek(localTimestamp)
| where ByPassDays <> ‘6.00:00:00’
| where ByPassDays <> ‘7.00:00:00’
| where localTimestamp > StartAlertTime
| where localTimestamp < StopAlertTime
| order by localTimestamp asc
Recent Comments